
La resiliencia es la capacidad de enfrentar y superar dificultades rápidamente, y en Pomelo, la hemos convertido en un pilar clave para garantizar que nuestra infraestructura siga funcionando ante cualquier adversidad. Nuestro compromiso es ofrecer a nuestros clientes una experiencia estable y confiable, sin interrupciones. Para lograrlo, implementamos estrategias que mantienen nuestra operación activa, minimizando el tiempo de inactividad y adaptándonos a un entorno tecnológico que cambia constantemente.
Conoce cómo lo logramos a continuación.
Construyendo una infraestructura preparada para escalar
El crecimiento de Pomelo nos plantea desafíos que requieren una infraestructura fuerte y bien preparada: a medida que avanzamos junto a nuestros clientes, gestionamos un volumen cada vez mayor de usuarios, emitimos más tarjetas y procesamos más transacciones. Esto también nos ha llevado a operar en más países y a colaborar con una red más amplia de proveedores, lo cual exige que nuestra infraestructura sea cada vez más compleja. Además, el crecimiento de nuestros equipos y servicios internos exige una coordinación eficaz para asegurar que todo funcione sin interrupciones.
Para responder a las crecientes necesidades de nuestros clientes sin comprometer la calidad del servicio, nuestra plataforma debe estar preparada para adaptarse, escalar y operar sin interrupciones.
— Diego Burgos, CTO de Pomelo.
Ante posibles fallos técnicos, la infraestructura de Pomelo debe ser capaz de detectarlos y gestionarlos en tiempo real, activando respuestas automáticas que minimicen el impacto en la experiencia del cliente. Poder mitigar estos fallos de manera rápida es clave para asegurar la confiabilidad y estabilidad de nuestra plataforma mientras seguimos creciendo.
Detectando puntos de falla críticos
La infraestructura de Pomelo está compuesta por varios componentes que dependen entre sí, lo cual aumenta tanto la complejidad operativa como el riesgo de fallas. Detectar estos puntos críticos es clave para aplicar patrones de resiliencia que fortalezcan nuestra plataforma. Algunas de nuestras recomendaciones para un enfoque proactivo son:
- Mapeo de dependencias e integraciones externas: Analizar en profundidad las relaciones entre los servicios internos y externos nos permite visualizar puntos críticos y cuellos de botella que podrían afectar el funcionamiento en caso de fallas. Por ejemplo, si uno de nuestros servicios depende de una API externa para validar información, una interrupción o demora en esa API podría ralentizar todo el proceso. Identificar esta dependencia como un punto crítico nos permite prepararnos y aplicar estrategias para reducir el impacto si el servicio externo falla.
- Monitoreo y observabilidad: Configurar un monitoreo en tiempo real y centralizar los logs nos ayuda a detectar fallas y anomalías de manera temprana. Además, la trazabilidad distribuida permite identificar con precisión los puntos de latencia en los flujos de transacciones.
- Experimentos de Chaos Engineering: Hacer pruebas de fallas controladas nos permite evaluar cómo reaccionan los componentes en situaciones extremas, ayudándonos a detectar vulnerabilidades y reforzar la infraestructura. Si querés aprender cómo lo implementamos en Pomelo, hacé click acá.
Implementando patrones de resiliencia
Una vez que identificamos los puntos críticos de nuestra infraestructura, aplicamos patrones de resiliencia para reforzar esas áreas y asegurarnos de que los servicios funcionen sin interrupciones. Estos patrones nos permiten reaccionar rápido ante fallas, reducir el impacto en los clientes y adaptarnos al crecimiento constante.
A continuación te compartimos algunos de los patrones clave que usamos para mantener nuestra infraestructura estable:
Circuit Breaker
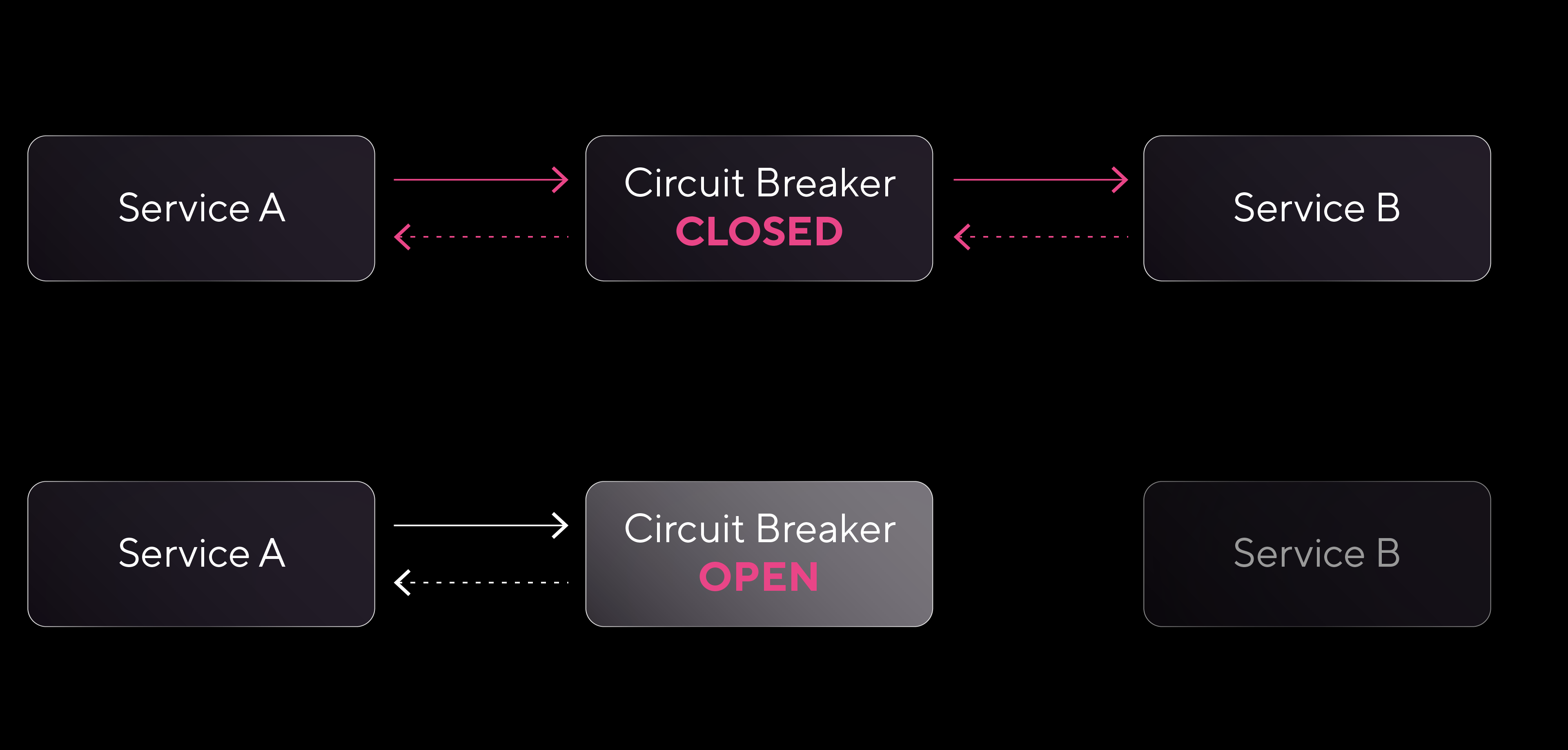
El Circuit Breaker es un mecanismo de protección pensado para bloquear las llamadas a un servicio cuando se detecta una cantidad consecutiva de errores, evitando así que las fallas se propaguen en cadena. En condiciones normales, el circuito está en estado cerrado, permitiendo que las solicitudes se procesen sin restricciones. Sin embargo, cuando un servicio empieza a fallar y el número de errores llega a un límite preconfigurado, el circuito pasa al estado abierto. En este estado, se bloquean las solicitudes hacia el servicio que falla y se devuelven errores de inmediato, evitando que el sistema siga intentando conexiones que probablemente van a fallar, lo que ahorra recursos.
Después de un tiempo en estado abierto, el Circuit Breaker pasa a medio abierto para realizar algunas solicitudes de prueba y verificar si el servicio se estabilizó. Si estas pruebas son exitosas, el circuito vuelve a cerrarse y se reanuda el flujo normal de solicitudes; si las pruebas fallan, el circuito permanece abierto.
Timeout and Retry
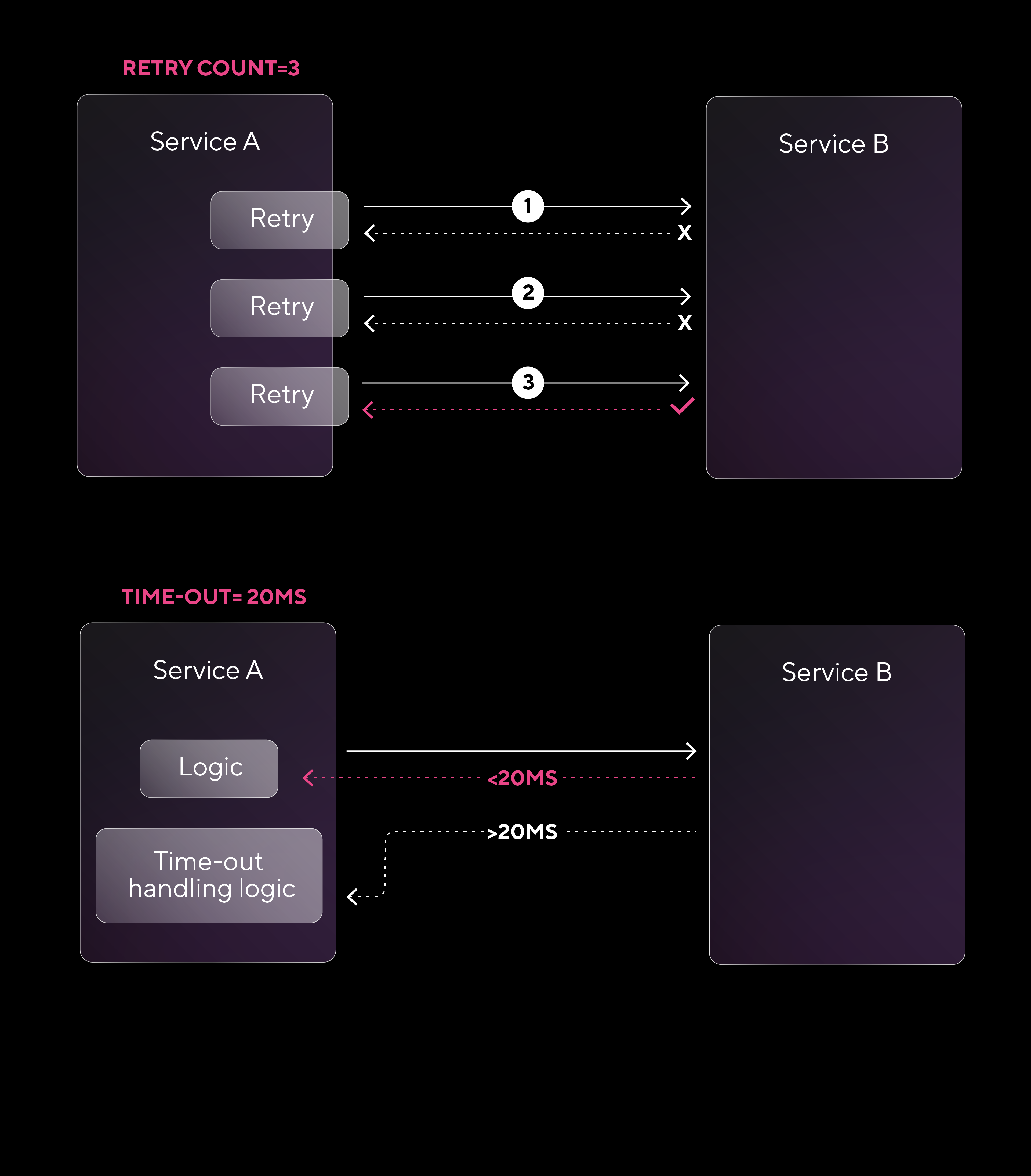
Cuando se realizan solicitudes a servicios, ya sean externos (como una API de terceros) o internos, dentro de nuestra propia infraestructura, factores como la latencia de red (el tiempo que tarda en transmitirse la información) o la falta de disponibilidad del servicio pueden hacer que esas solicitudes se demoren o queden sin respuesta.
Estos retrasos pueden generar cuellos de botella que afectan el rendimiento general. Para manejar este tipo de situaciones, se utiliza el patrón Timeout and Retry, que establece un tiempo límite (timeout) para cada operación. Si una operación no se completa en ese tiempo, se considera fallida y se reintenta (retry) un número específico de veces antes de devolver un error.
Para aplicar el patrón Timeout and Retry de forma efectiva, se recomienda:
- Configurar tiempos de espera adecuados: Ajustar el timeout según la latencia esperada, evitando tiempos demasiado cortos que disparen reintentos innecesarios o tiempos muy largos que afecten la capacidad de respuesta.
- Limitar la cantidad de reintentos: Definir un número máximo de retries para evitar bucles infinitos y controlar la carga general de la infraestructura.
- Usar backoff exponencial: Aumentar gradualmente el intervalo entre reintentos ayuda a reducir la presión sobre el servicio y mejora las probabilidades de recuperación.
- Asegurar la idempotencia: Verificar que los reintentos no generen efectos no deseados en los datos, garantizando que los resultados sean consistentes aunque una operación se intente varias veces.
Fallback
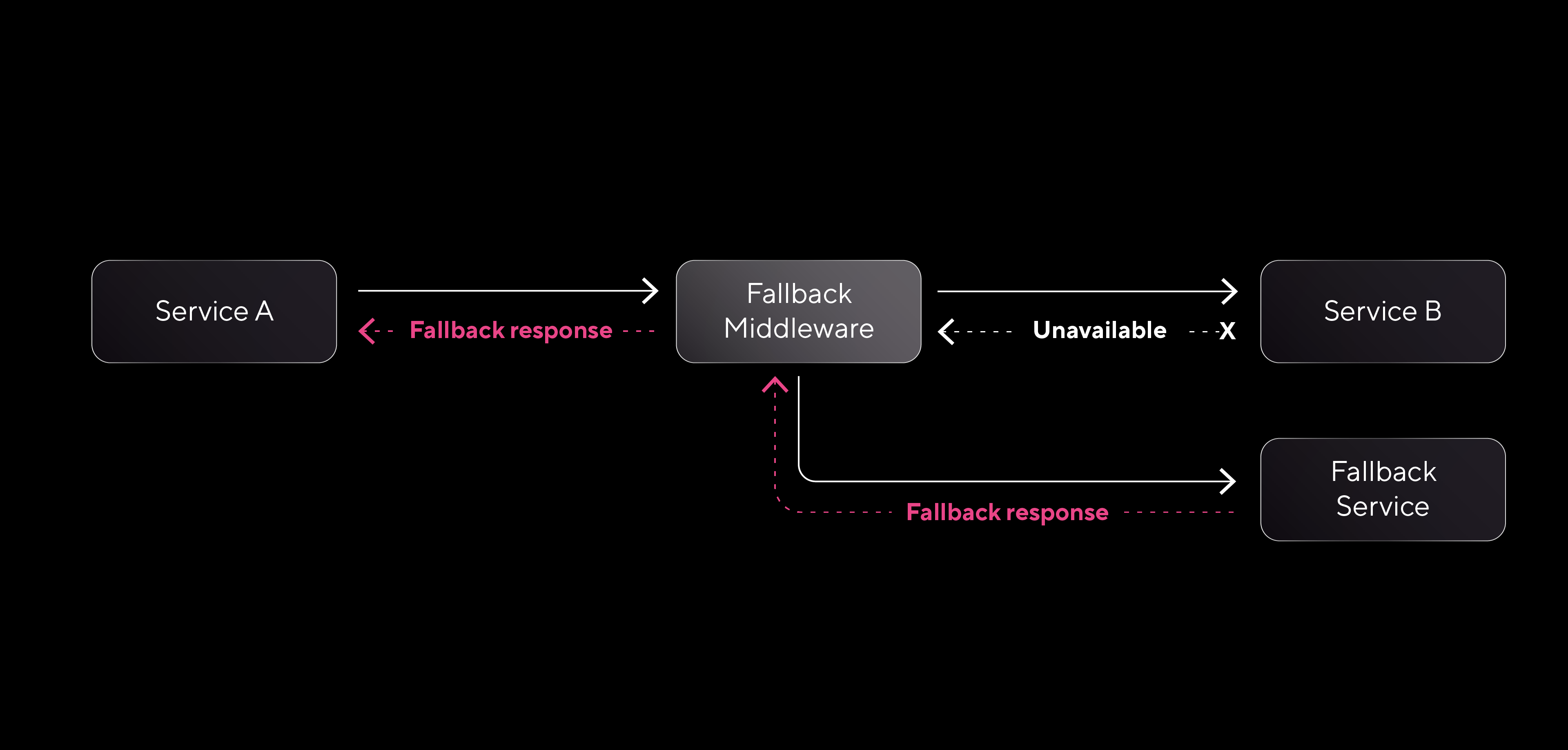
El patrón Fallback garantiza que nuestros clientes reciban una respuesta útil cuando uno de nuestros servicios no está disponible, ayudando a evitar que las fallas se propaguen y se mantenga la continuidad en el flujo de datos. Este patrón permite devolver una respuesta alternativa (fallback response) cuando un servicio no puede procesar una solicitud.
Para implementar el patrón Fallback de manera efectiva, se recomienda seguir estos pasos:
- Definir respuestas de fallback adecuadas: Determinar qué tipo de respuesta alternativa se usará en cada caso. Las opciones más comunes incluyen devolver datos en caché, valores por defecto o mensajes de error que informen a los consumidores sin interrumpir la operación.
- Implementar middlewares: Crear componentes intermedios que detecten condiciones de falla y activen automáticamente la acción de fallback configurada. Estos componentes funcionan como filtros, identificando cuando un servicio no responde y devolviendo la respuesta alternativa.
- Revisar y ajustar las respuestas: Es fundamental revisar regularmente las respuestas de fallback para asegurar que sigan siendo relevantes y efectivas, dado que los escenarios de uso y los requisitos del servicio pueden cambiar con el tiempo.
Bulkhead
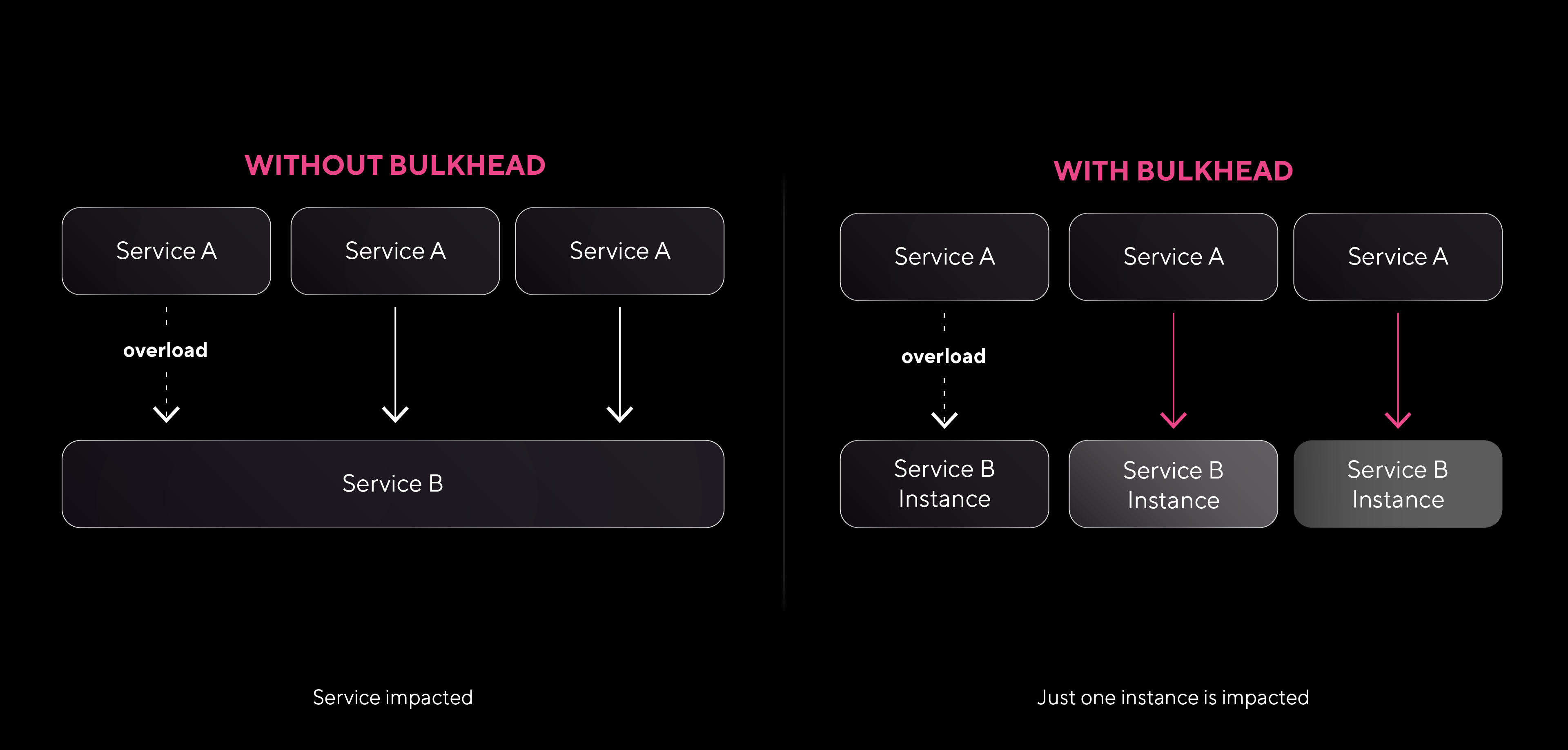
El nombre “bulkhead” proviene de la arquitectura naval, donde los mamparos dividen un barco en secciones independientes y selladas; de esta manera, si una sección se inunda, las demás permanecen seguras. En tecnología, este enfoque busca el mismo efecto: evitar fallos en cadena limitando el impacto de una falla.
Para aplicar el patrón Bulkhead, se recomienda dividir los recursos en “compartimentos” independientes. En una infraestructura compuesta por múltiples servicios, esto puede implicar la creación de pools de recursos separados (como hilos, conexiones o memoria) para distintos servicios o clientes. Por ejemplo, si un servicio experimenta una alta demanda que sobrecarga sus recursos, los demás servicios no se verán afectados porque cada uno tiene su propio “compartimento” de recursos. Esto permite que, aunque una parte de la infraestructura esté bajo presión o falle, el resto siga funcionando con normalidad.
Algunos puntos clave para implementar el patrón Bulkhead son:
- Asignar pools de recursos dedicados: Configurar pools de hilos, conexiones o memoria independientes para los servicios que se consideren críticos o de alto riesgo. De esta forma, si un pool se satura, los recursos de otros servicios no se ven comprometidos.
- Monitorear la capacidad y el uso de los recursos: Implementar un monitoreo en tiempo real para identificar rápidamente si algún compartimento está alcanzando su límite de capacidad. Esto permite realizar ajustes preventivos o agregar recursos según sea necesario.
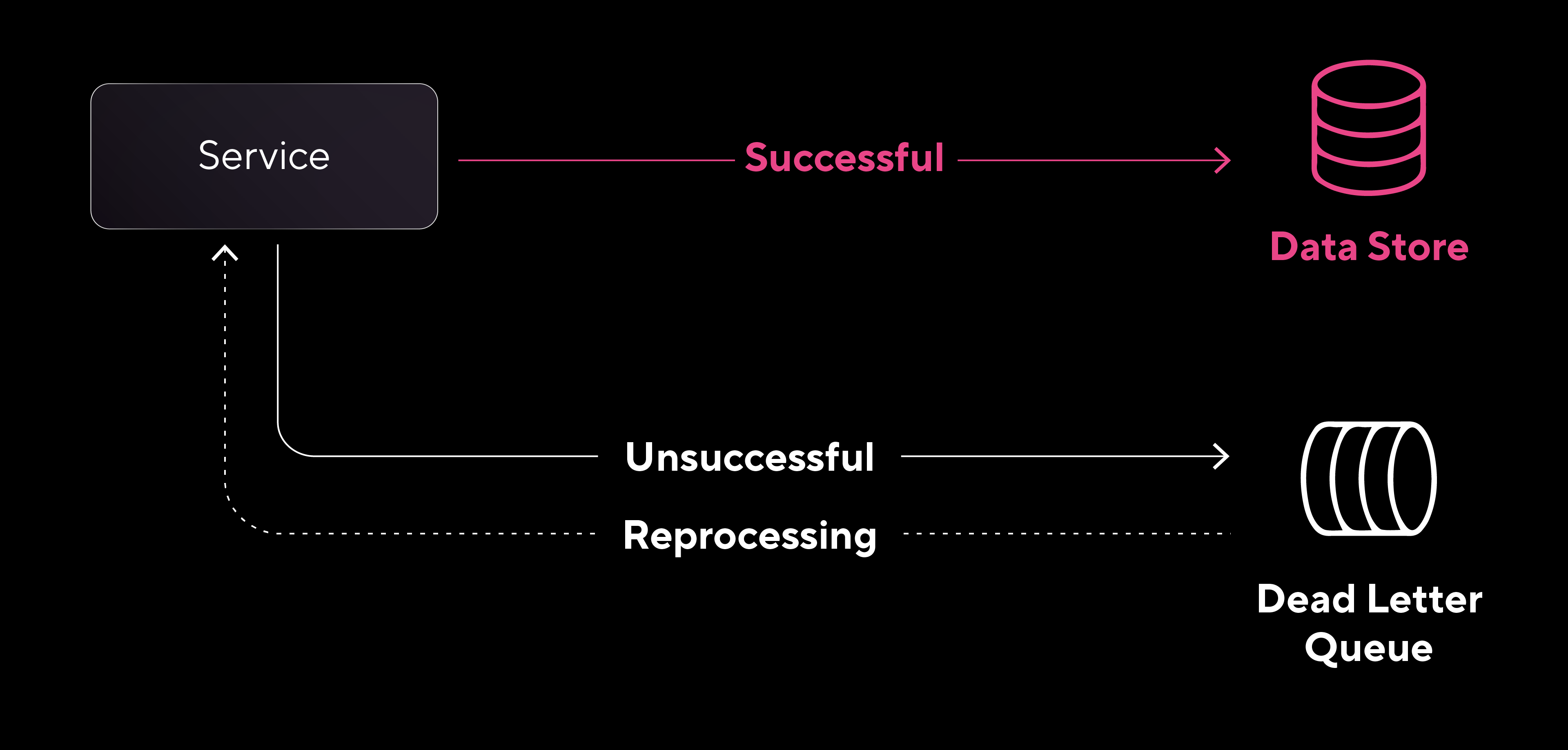
Dead Letter Queue
El patrón Dead Letter Queue (DLQ) se utiliza para aumentar la resiliencia de los servicios que procesan datos, permitiendo que se recuperen de incidentes que impiden el procesamiento o la escritura de información, sin perder datos en el proceso.
Una Dead Letter Queue funciona como un “área de espera” para las solicitudes que no pueden ser procesadas correctamente. En lugar de interrumpir o sobrecargar el flujo de datos con solicitudes problemáticas, se desvían a la cola de dead letters, mientras el servicio continúa procesando el resto de las solicitudes válidas.
Existen varias razones por las cuales una solicitud puede terminar en una dead letter queue:
- Estructura de datos inválida: La estructura de la solicitud no coincide con lo esperado.
- Valores fuera de rango o inesperados: Algunos campos contienen valores que no cumplen con las expectativas.
- Problemas al escribir en el almacén de datos: No es posible escribir los datos en el destino previsto debido a fallas en la conexión, credenciales inválidas o problemas de disponibilidad del sistema.
El Dead Letter Queue Pattern asegura que estas solicitudes problemáticas no interfieran con el flujo normal y facilita la depuración y resolución de problemas. Al analizar las solicitudes almacenadas en la DLQ, los equipos de tecnología pueden investigar qué generó el error, diagnosticar el problema y tomar las medidas necesarias para corregirlo.
Una vez resuelta la causa del problema, es posible reintentar el procesamiento de las solicitudes en la DLQ, asegurando que los datos no se pierdan y se procesen correctamente. Aunque este patrón se utiliza comúnmente en plataformas de event streaming, es útil en cualquier servicio orientado a datos que busque mejorar su resiliencia y asegurar la integridad de las solicitudes.
La resiliencia no es opcional
En Pomelo, construir una infraestructura resiliente no es solo un objetivo, sino una necesidad para responder al crecimiento constante y asegurar la continuidad del servicio. Estos principios, que aplicamos en nuestra infraestructura, también son recomendaciones clave para quienes buscan priorizar la estabilidad y la continuidad:
- Asegurar la independencia entre servicios: Dividir la infraestructura en compartimentos independientes evita que una falla en un servicio afecte a los demás. Aplicar el patrón Bulkhead ayuda a gestionar recursos de forma aislada, limitando el impacto de fallas y evitando sobrecargas.
- Configurar tiempos de espera y reintentos inteligentes: Definir timeouts y reintentos controlados permite detectar fallas rápidamente y evitar intentos innecesarios que pueden saturar el sistema.
- Implementar mecanismos de corte para protección:Los Circuit Breakers cortan la conexión con servicios que no responden, protegiendo la infraestructura al reducir los tiempos de espera y manteniendo los servicios críticos en funcionamiento.
- Ofrecer respuestas de respaldo ante fallas:El patrón Fallback permite devolver respuestas alternativas (como datos en caché) cuando un servicio falla, asegurando que los consumidores obtengan una respuesta útil sin interrupciones visibles.
- Favorecer mensajes asíncronos: El uso de mensajes asíncronos junto con el patrón Dead Letter Queue aumenta la tolerancia a fallos y optimiza el rendimiento, ya que permite manejar las solicitudes problemáticas sin afectar el flujo principal de procesamiento, reduciendo así la dependencia entre servicios.
Estos principios nos permiten construir una infraestructura robusta, preparada para un entorno en constante cambio. En Pomelo, la resiliencia es la base de nuestra operación. Cada decisión y cada patrón implementado están orientados a mantener nuestros servicios estables y confiables, incluso bajo alta presión o ante fallas inesperadas.
