
Hace ya varios años, las empresas de tecnología comenzaron a implementar diferentes métodos para exprimir y obtener valor de los datos que fluyen por sus aplicaciones para ayudar a la toma de decisiones. En este artículo compartiremos cómo encaramos la implementación de nuestro Data Lake Pomelero. Y, sobre todo, cómo hicimos para lograr ponerlo productivo en tan poco tiempo. Hacia el final vas a encontrar el video con la charla completa para que no te pierdas ningún detalle. ¡Te invitamos a que disfrutes de este paseo por nuestro lago!
¿Qué es un Data Lake?
El término Data Lake o Lago de Datos surge por el año 2010, haciendo referencia a la analogía a los datos que “llenan el lago” desde distintos tipos de orígenes. Es decir datos estructurados y no estructurados centralizados en un mismo lugar.
¿Por qué un Data Lake?
En Pomelo tenemos datos con diferentes orígenes que pueden darnos insights invaluables si logramos analizarlos. Se trata de mostrar el valor que puede obtenerse con los datos y con ello tener un enfoque data-driven para la toma de decisiones.
Ahora, lo importante de este artículo no es solo decir que hemos construido nuestro data lake rápidamente, sino qué prácticas y qué lineamientos tuvimos que llevar a cabo para poder hacerlo con calidad y de la forma más ágil posible. Entonces contestando la pregunta ¿cómo lo construimos en 3 meses? En gran parte Arquitectura.
Como primer paso armamos la arquitectura del proyecto en sí, en donde definimos:
- gobierno del proyecto;
- cuáles serán los tipos de datos de origen;
- cómo vamos a obtener los datos;
- cuál será la frecuencia;
- cómo y dónde se almacenará;
- cómo se utilizarán;
- seguridad del dato;
- gobierno del dato
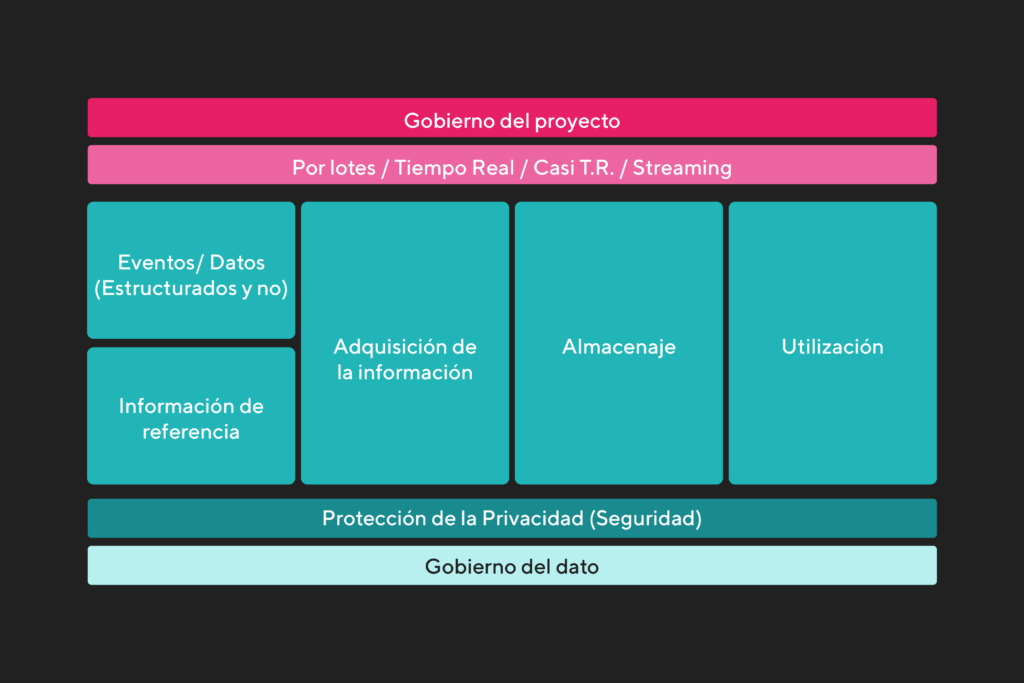
Podemos decir entonces que la construcción de nuestro data lake fue guiada por arquitecturas, y en este caso la de AWS Lake House. Allí tenemos un lago de datos que interactúa con diferentes servicios y, a su vez, estos se comunican entre ellos. Así es como desde un principio nuestra visión no es solo tener el data lake sino evolucionarlo y llevarlo a un Lake House.
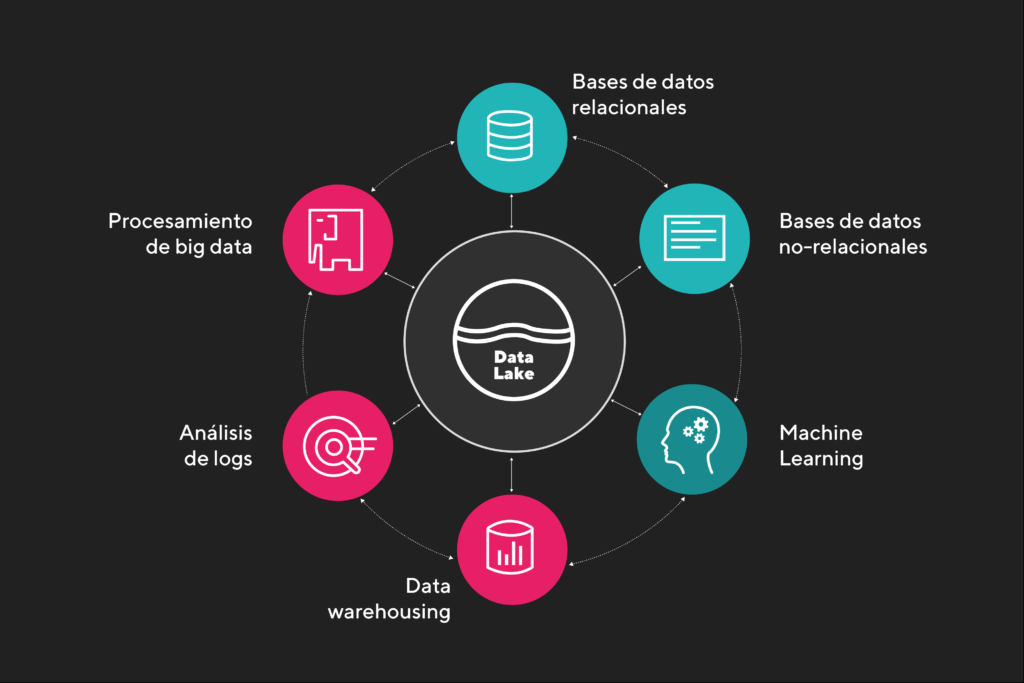
Un Lake House básicamente se logra cuando cuentas con las bondades que nos ofrece el data lake, junto con los beneficios que ofrece el data warehouse y su capa de negocio.
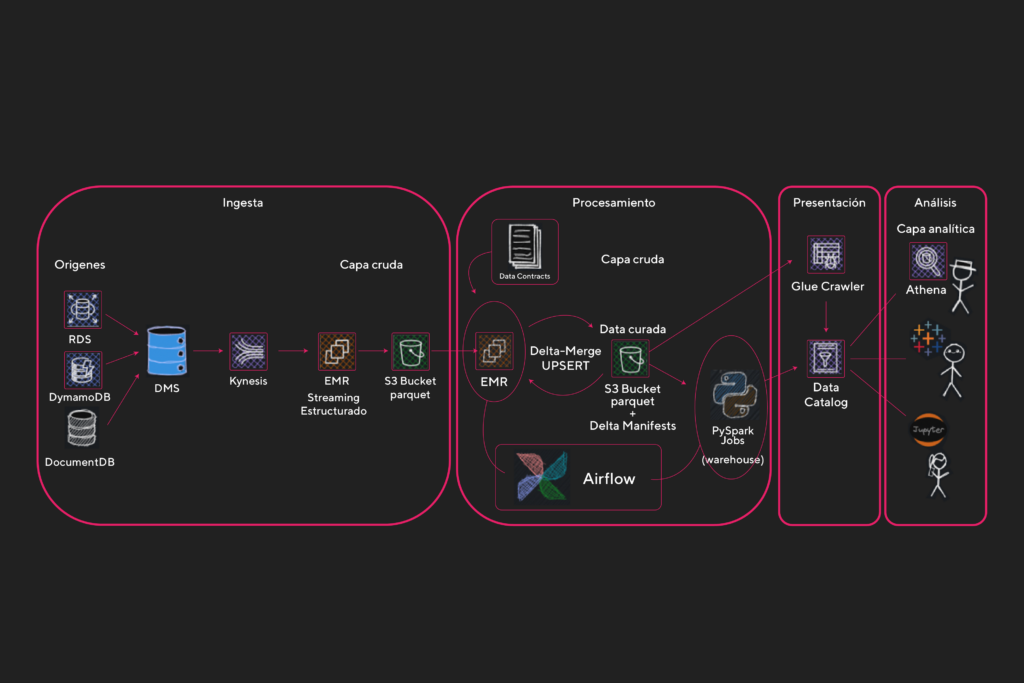
Servicios y herramientas utilizadas
A continuación veremos qué servicios y herramientas utilizamos para la construcción de nuestro Data Lake en sus distintas capas:
- Ingesta
- Origen de datos: RDS, DynamoDB, DocumentDB
- Kinesis Data Stream
- Data Migration Service
- EMR Cluster
- Almacenamiento
- Procesamiento
- Presentación
- Análisis
Herramientas
Ingesta
Es la capa en donde nos conectamos a los diferentes orígenes de datos, tales como RDS, DynamoDB y DocumentDB. Lo que hacemos es conectar estas bases relacionales y no relacionales a un Kinesis Data Stream. En el caso de los RDS a través del servicio Database Migration Service o DMS.
DMS es un servicio que se compone de 3 partes fundamentales:
- Instancia de replicación (el poder de cómputo)
- Endpoints (se definen el origen y destino)
- Tarea de replicación (junta los componentes anteriores para llevar a cabo la replicación)
Entonces, el destino de nuestra tarea de DMS será el Kinesis Data Stream, el cuál tiene la funcionalidad de recibir todos los eventos que sucedan en la base de datos de origen y retenerlos en un streaming durante 24 horas (tiempo default y mínimo que ofrece AWS con el menor costo).
Aquí entra en juego el servicio EMR Cluster ejecutando un programa que utiliza Pyspark.
EMR, Elastic Map Reduce por sus siglas, es un servicio que nos permite armar clusters de computadoras en la nube para la ejecución de un programa que necesitemos ejecutar, como por ejemplo un programa con PySpark (Spark con Python).
Apache Spark es un motor de código abierto que nos permite procesar grandes volúmenes de datos utilizando cómputo distribuido, y se presenta con interfaces que son compatibles con lenguajes como Python, Java, Scala, .Net, entre otros.
Los clusters de EMR nos permiten aprovechar el cómputo distribuido de Spark, el cual utilizamos en Python con la librería PySpark. Gracias a ello podemos procesar grandes volúmenes de datos de forma escalable y eficiente. Lo que haremos con el programa será leer el stream de Kinesis en micro-batches utilizando librerías para streaming estructurado… pero ¿qué es esto de streaming estructurado y micro-batches? Bueno, veamos un poco estos términos y cómo los usamos:
Micro-batches y Streaming Estructurado
En Pomelo decidimos llevar a cabo esta solución utilizando AWS. Pero fuimos un poco más allá de lo común y nos desafiamos a que todos nuestros datos tengan un delay Near to Real Time o NRT. Esto quiere decir, que desde que se origina el dato hasta llegar al data lake, hay un tiempo de retraso de entre 1 a 60 minutos. Para lograr esto procesamos los datos de orígenes del ya mencionado Kinesis Data Streaming en micro-batches o pequeños lotes de datos que se acumulan y procesan cada 30 segundos dentro del programa Pyspark.
Esto lo logramos utilizando una librería de python que nos permite consumir los Kinesis con Pyspark y manipular estos micro-batches como si fuesen DataFrames de Spark. Y, a su vez, al ser estructurado se guardan checkpoints, lo que nos permite reanudar el procesamiento desde el último batch en caso de un error o falla. El programa Pyspark escribe el micro-batch en un bucket de S3, el servicio de almacenamiento de AWS.
Almacenamiento
S3 es el servicio de almacenamiento que utilizamos para persistir los datos crudos en nuestro lago de datos. El programa PySpark tiene las instrucciones para escribir el micro-batch en un bucket de S3 en formato parquet, comprimido en snappy y particionado por el timestamp que toma el dato al entrar al Stream de Kinesis en las particiones year/month/day.
Procesamiento
En esta capa aplicamos procesamiento a los datos crudos, nuevamente utilizando el poder de cómputo de los clusters de EMR, que son lanzados y orquestados con Apache Airflow, un manager de flujos de trabajos open source que es usado para orquestar los pipelines de datos con DAGs (Grafo acíclico dirigido) programados en Python. En nuestra infraestructura desplegamos Airflow en Kubernetes, lo cuál fue un gran desafío.
Volviendo al procesamiento de datos utilizaremos PySpark junto con la librería Delta Lake, y ya que la mencionamos hablemos un poco sobre esta.
Delta Lake y UPSERTS
Delta Lake es la librería que nos permite tener un mejor manejo de los eventos CDC (change data capture) de las bases de datos y realizar el UPSERT (insert + update) de los datos en nuestro lago de datos en NRT. Recordemos que lo que leemos en nuestro bucket de S3 son datos en formato parquet que vienen del streaming de los eventos de las bases de datos conocidos como CDC. Por lo tanto Delta Lake nos proporciona lo que se conoce como transacciones ACID (atomicidad, consistencia, aislamiento y durabilidad por sus siglas en inglés), un control escalable de metadatos y la unificación del procesamiento de datos de streaming y por lotes (micro-lotes en nuestro caso).
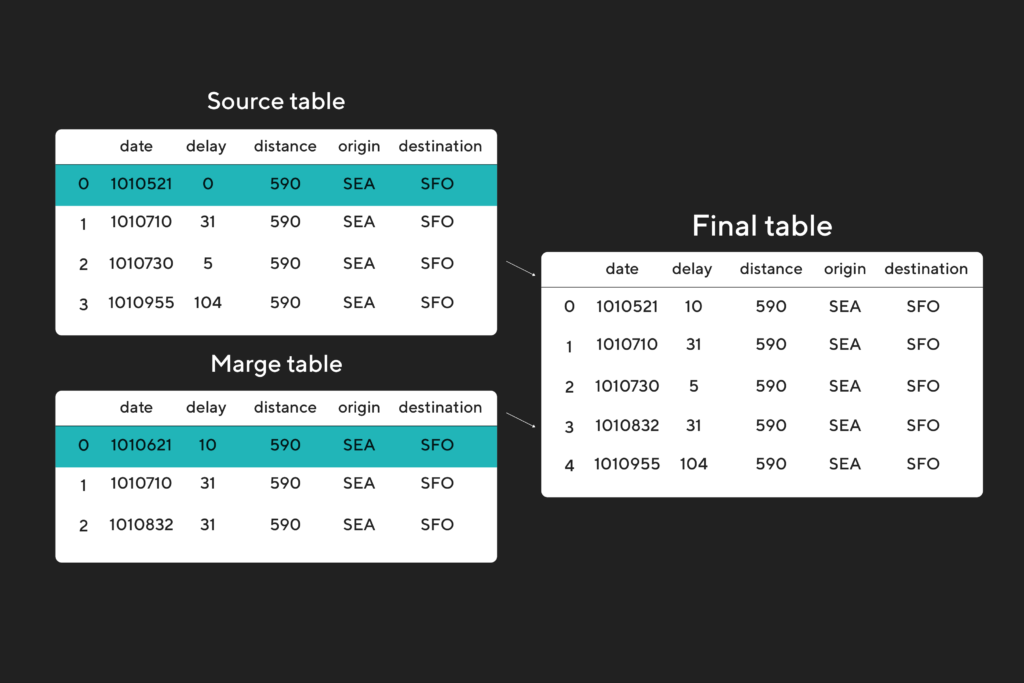
Una vez procesados los datos se escriben en formato Delta en otra ruta de S3 en donde almacenamos los datos curados.
Presentación
En la capa de presentación tomamos todo lo que esté en la capa curada y lo llevamos al catálogo de datos de Glue utilizando un Glue crawler. El crawler es una especie de escáner que analiza los archivos en una ruta de S3 específica y, en base a los metadatos de los archivos, arma la estructura de una tabla y la plasma en una base de datos definida en el catálogo de Glue. Glue Data Catalog es un servicio que nos permite crear índice de ubicación, esquema y métricas de ejecución de nuestros datos. El catálogo es compatible con el software de data warehouse de código abierto Apache Hive y le sirve este como metastore, es decir, como un repositorio centralizado de metadatos.
En nuestro caso le pasaremos al crawler la ruta de S3 en dónde se encuentran nuestros archivos de datos escritos con el proceso Delta. Los crawlers de Glue son compatibles con los manifiestos generados por Delta y serán estos archivos lo que use de índice para armar cada tabla del catálogo. Podemos también programar un crawler para que se ejecute con una frecuencia definida. Por ejemplo, cada día a la madrugada, para que se actualice la estructura de cada tabla por si la misma ha sido alterada en el origen por un DDL (como un ALTER TABLE que agregue una nueva columna por ejemplo). Aunque también hay alternativas programáticas para realizar esto sin utilizar o depender de los servicios de Glue y hacerlo directamente con Python y PySpark.
Análisis
Una vez que tenemos nuestro catálogo de datos de Glue con esquemas, los mismos pueden ser consultados directamente desde el servicio de Athena, el que nos permitirá ver y consultar las distintas bases de datos y tablas del catálogo utilizando SQL. Athena está basado en PrestoSQL por lo tanto su sintaxis es muy similar.
El catálogo de datos de Glue es bastante versátil y nos permite conectar diferentes servicios o herramientas de análisis de datos a través de Athena para generar reportes y dashboards, como lo que realizamos con Tableau y Superset. O también, directamente conectarlo a un servicio como SageMaker de AWS para crear y entrenar modelos de machine learning.
Condimentos extra para velocidad Pomelo
Hasta aquí hemos compartido los diferentes servicios y herramientas que utilizamos para armar el Lakehouse, pero la realidad es que eso es solo una pequeña parte de los requisitos ya que (spoiler alert) la otra cara de implementar estos servicios en la nube es que requieren una buena gestión de permisos y roles, grupos de seguridad, autenticación y muchos temas que nos agregan complejidad. Sobre todo al lidiar con datos sensibles o que siguen regulaciones como el Standard PCI-DSS (Payment Card Industry Data Security Standard).
Es por eso que la agilidad y velocidad del proyecto es en gran parte gracias al trabajo en equipo. Contamos con muchísimo apoyo de equipos como Infraestructura, Compliance, Ciberseguridad, que velan por quitar esas grandes piedras de nuestro camino y nos permiten concentrarnos puramente en los datos y su procesamiento de calidad.
Next Steps [spoiler alert]
Mostramos en esta publicación cómo armamos el Data Lake y luego pasamos a tener un Data Lakehouse, pero esto no termina aquí, estamos en constante evolución y como muchos equipos de tecnología apuntamos a la vanguardia y no nos quedamos quietos.
Para contar un poco lo que se viene, vamos a contar un poco sobre Data Mesh.
En Pomelo consideramos que es importante disponibilizar a través del uso de patrones la automatización de la infraestructura operativa de todo los objetos creados en AWS, así como la gobernanza de estos objetos en términos de observabilidad, seguridad, compliant. Y, finalmente permitirle a los usuarios de negocio que en su dominio particular puedan autoservirse de los datos de pomelo.
La implementación tecnológica de estos tres casos de uso: infraestructura, gobernanza y autoservicio (del inglés, self service) pasa por la creación de un Data Contract. El data contract no es más que un archivo json que tiene claves y valores con todos los elementos necesarios para que una API pueda automatizar la gestión de la creación de los componentes de infraestructura, que en Pomelo los tendremos expuestos a través de Rocket como mecanismo de centralización y gestión. Pero todo esto lo veremos el próximo episodio!
¡Ahora sí, el video con todo el detalle de cómo construimos el Data Lake Pomelero! 👇
