
Las decisiones basadas en datos son un hecho desde los inicios en Pomelo. Y por eso, decidimos ir por más: construir un modelo revolucionario que recomienda no solo cuál es la fuente de datos más adecuada para cada necesidad, sino que también aborda la seguridad, certificación y validación de los datos de manera integral y automatizada.
La evolución hacia un enfoque data driven es inminente y la gobernanza se vuelve cada vez más crucial tanto para los equipos de datos como para las personas usuarias, por lo que es importante mantenerse a la vanguardia de las tendencias emergentes y aplicarlas de manera que beneficie a las organizaciones.
Seguramente ya te estarás preguntando, ¿cómo integraron un sistema de recomendación en Tableau?, ¿lograron embeber un modelo de IA?, ¿qué eficiencias trajo esta implementación? En este artículo te vamos a contar cómo lo logramos en Pomelo.
Transformando la gestión de datos
Al adoptar un enfoque data driven, las empresas no solo mejoran la toma de decisiones estratégicas, sino que también democratizan el acceso a la información. Este cambio en el paradigma está generando un aumento en el uso de herramientas analíticas. En este contexto, Tableau se destaca como la poderosa plataforma de visualización en Pomelo, así como en muchas otras compañías.
Reconociendo que Tableau no es sólo una herramienta interna, sino que también impacta directamente en la experiencia de nuestros clientes a través de los dashboards disponibles, nos comprometimos a mantenerlo en óptimas condiciones. Sin embargo, este compromiso no se detiene en el simple mantenimiento del software, sino que nos impulsa hacia la búsqueda constante de mejoras y eficiencias.
Es así como nos enfrentamos a un gran desafío: la creación de un sistema de recomendación y automatización integrado en Tableau, diseñado para revolucionar la manera de interactuar y mejorando así la eficiencia y la experiencia de las personas usuarias.

Primeros pasos
Para abordar este desafío comenzamos por analizar en profundidad la infraestructura de Tableau Server. Como primeros pasos en nuestra estrategia de automatización, nos enfocamos en el desarrollo de automatismos, apoyándonos con las APIs de Tableau y obteniendo como resultados procesos que lograran:
- el reemplazo de credenciales de manera segura;
- la detección proactiva de incidentes;
- la modificación de frecuencias de ejecución de tareas;
- alertas y mensajes automáticos sobre estado de salud del servidor y el cluster;
- procesos de limpieza y mantenimiento regular, y más.
Estas primeras soluciones no solo mejoraron la eficiencia operativa, sino que también nos acercaron al cumplimiento de los estándares de gobernanza de datos. Además, nos proporcionaron una visión integral del rendimiento de Tableau Server, garantizando su operatividad en óptimas condiciones en todo momento.
¿Análisis de fuentes de datos?
Reconociendo la importancia de las fuentes de datos en Tableau, así como el acceso a la certificación y validación de esos datos por un profesional, como pilares fundamentales para preservar su integridad y confiabilidad, nos propusimos ir un paso más allá. Nos desafiamos a desarrollar un sistema que no solo garantizara la certificación profesional de nuestras fuentes de datos, sino que también revolucione la forma en que interactuamos con la información, proporcionando recomendaciones y sugerencias, entre otras funcionalidades innovadoras.
Apoyándonos en el acceso a la valiosa metadata de Tableau y aprovechando los sólidos conocimientos en Python de nuestro equipo de Business Intelligence, ideamos y desarrollamos un primer proceso que realice un profundo análisis de sus atributos:
- ¿Cuánto pesaba el extracto?
- ¿Era coherente la cantidad de filas?
- ¿Tenía una nomenclatura adecuada según los estándares de calidad?
- ¿Estaban correctamente configuradas las actualizaciones?
- ¿Funcionaba correctamente el extracto?
Tras validar automáticamente todas estas incógnitas, en menos de un minuto ya obteníamos una respuesta clara sobre su estado y aptitud. Esta automatización mejoró la eficiencia del equipo,y también empoderó a las personas usuarias con respuestas rápidas y precisas, facilitando el uso ágil y confiable de los datos.
¿Y cómo llegamos al sistema de recomendación?
Hasta el momento habíamos logrado eficiencia en distintos aspectos con los procesos y automatizaciones que implementamos. Sin embargo, aún teníamos por resolver la gran problemática que enfrentamos todos en Tableau Server: las fuentes de datos duplicadas, similares, desordenadas y desconocidas a lo largo de todos los proyectos. Este desafío dio origen al sistema de recomendación que lograría brindar una experiencia de valor innovadora, así como agilizar y eliminar por completo las tareas manuales relacionadas con el análisis de fuentes de datos.
Nos enfrentamos entonces al desafío de integrar todo lo que habíamos desarrollado hasta el momento con un modelo completamente nuevo para nosotros. Aunque surgieron varias alternativas, estábamos decididos a encontrar aquella que pudiera integrarse con nuestro proceso y cuyos resultados pudieran ser modelados con precisión. Fue así como identificamos que Python sería la opción adecuada para desarrollar e implementar la lógica necesaria. Sin embargo, nos preguntamos qué más debíamos considerar.
¿Bases de datos de vectores?
La pregunta sobre qué datos necesitábamos analizar guió nuestro camino hacia la que sería la solución final. La mayoría de los datos provendrían de Athena, PostgreSQL, y otros sistemas de almacenamiento que alimentan nuestro data lake. Entonces, surgió la necesidad de una infraestructura capaz de manejar estos datos de manera eficiente y escalable. De esta manera empezamos a considerar la implementación de bases de datos de vectores.
Estas bases de datos representan una forma innovadora de almacenar y gestionar información, especialmente cuando se trata de datos de alta dimensionalidad. A diferencia de las bases de datos tradicionales, que almacenan datos en tablas bidimensionales, las bases de datos de vectores están diseñadas para trabajar eficientemente con datos que se pueden representar como vectores numéricos. Esto logra una capacidad de procesamiento y análisis de grandes volúmenes de datos de manera más eficiente y rápida que las bases de datos tradicionales, lo que la hace especialmente adecuada para entornos con datos complejos y de alta dimensionalidad.
Después de considerar diversas opciones, optamos por Chroma como nuestra solución. Chroma es una base de datos de vectores que ofrece un rendimiento excepcional y una flexibilidad notable para trabajar con datos de alta dimensionalidad. Su capacidad para manejar grandes volúmenes de datos y su eficiencia en el procesamiento de consultas lo convirtieron en la opción ideal para nuestro proyecto. Pero lo que realmente destacó en nuestra elección fue su capacidad para integrarse de manera fluida con potentes modelos de procesamiento del lenguaje natural.
Entonces, para potenciar aún más esta combinación, incorporamos Open AI como engine junto a Chroma.
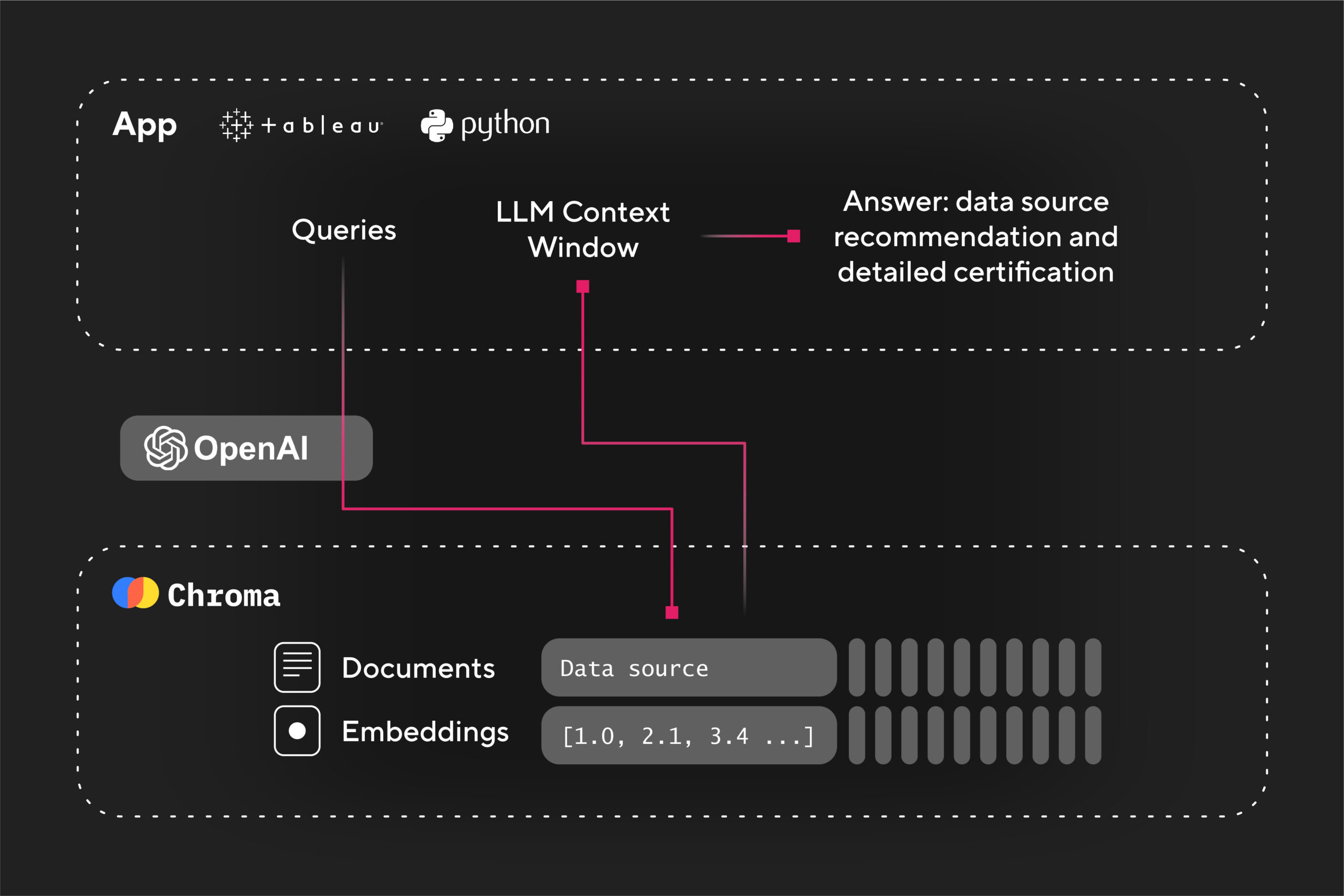
¿Open AI y Tableau juntos?
¡Sí! Las automatizaciones de Tableau que habíamos construido en un inicio evolucionaron hasta el punto de que ahora son impulsadas por la inteligencia artificial de Open AI. Pero, ¿cómo funciona esto? Veámoslo paso a paso:
- El proceso recibe la fuente de datos de Tableau que deseamos consultar.
- Chroma explora la base de datos de vectores en busca de aquellos que estén disponibles, certificados y en producción.
- Luego, el proceso interactúa con Open AI y nos entrega resultados que formateamos automáticamente en Python.
- Por último, generamos respuestas en lenguaje natural con recomendaciones sobre qué fuente de datos de Tableau utilizar y los porcentajes de similitud entre sí.
La sinergia entre Chroma y Open AI nos permitió alcanzar niveles inéditos de eficiencia y precisión en la gestión de datos, allanando el camino hacia una toma de decisiones más informada y estratégica. Transformamos procesos manuales que solían llevar hasta 2 horas de trabajo en una tarea automatizada de apenas 2 minutos. Además, esta solución está preparada para manejar todos los extractos, desde los iniciales hasta los que se sumen con el tiempo, complementando el conocimiento interno del equipo y permitiendo que la IA asuma esa responsabilidad.
Gracias a esta integración, ahora las validaciones y sugerencias se realizan de manera instantánea y precisa, optimizando nuestro flujo de trabajo y asegurando la calidad de los datos de manera eficiente. Desde su implementación, este proceso se convirtió en estándar para todas las fuentes de datos nuevas, lo que contribuyó en que más del 38% hayan sido sometidas al nuevo flujo antes de activarse.
¡Llegamos al final!
El proceso logrado agrega valor a todos, proporcionando métricas más rápidas, seguras y confiables. Esto se traduce en una mayor satisfacción por parte de los clientes al recibir información precisa y acceso a datos relevantes y confiables para sus decisiones.
Este enfoque innovador no se limita solo a Tableau; su potencial puede ser extendido a otros data products. Un próximo paso podría implicar la integración de esta solución en nuestra estrategia de Data Mesh, lo que permitiría replicar y escalar esta eficiente gestión de datos en todo nuestro ecosistema de información.
