
Muchos procesos relacionados con el alta de nuevos clientes, servicios o proveedores requieren de la creación de infraestructura. Dicha infraestructura suele ser estándar, pero debe ser parametrizada según las líneas de negocio o las áreas de servicio que las necesite.
Normalmente estos pedidos son canalizados al área de Infraestructura, Plataforma o Seguridad, introduciendo demoras de cara al cliente o negocio, y sobre carga operativa a los departamentos que las implementan. Eso es lo que evitamos al máximo en Pomelo – entonces, decidimos anticiparnos para disminuir el tiempo de altas de nuevos clientes.
En este artículo, compartimos una experiencia sobre Rundeck y AWS Service Catalog que tuvo el objetivo de ofrecer más autonomía a quien necesite llegar a la infraestructura necesaria.
Además de explicar qué y cómo hicimos, con tooodos los detalles, encontrarás los resultados que obtuvimos al final del blog post. Ya adelantamos que son increíbles! 😎
Disfrute!
Qué nos propusimos?
Buscamos la forma de orquestar estos procedimientos para que la infraestructura necesaria para dar un servicio pueda crearla quien la necesite. En el menor tiempo posible, con la mayor independencia posible y sin requerir conocimientos específicos sobre la infraestructura creada. Todo de forma segura, simple y estandarizada, como debe ser 🙌
Nuestro procedimiento debía acelerar los tiempos de creación, minimizar la intervención del departamento de Infraestructura, cumplir con los estándares estrictos de seguridad, minimizar posibles riesgos o errores y ser a la vez amigable y sencilla al usuario.
Así mismo el tiempo de desarrollo de la solución completa debía acompañar la velocidad del negocio, por lo que optamos por utilizar un stack de soluciones ya existentes, que nos permitieran brindar las funcionalidades necesarias en un tiempo muy corto, sin necesidad de esperar los tiempos necesarios para el desarrollo de una solución completa desde cero.
Para ello, buscamos crear un stack de soluciones, que en su combinación creen la solución final deseada:
- Rundeck para orquestar tareas y determinar permisos de usuarios;
- AWS IAM para gestión de permisos de acceso;
- AWS Boto3 para gestionar las distintas funciones;
- y AWS Service Catalog para la implementación de estándares de infraestructura.
Y qué son esas herramientas?
Rundeck es una herramienta de automatización de tareas, que permite orquestar series de tareas complejas y presentarlas para una ejecución simple, segura y self service, con un muy intuitivo manejo en su interfaz de usuario.
Por otro lado, Service Catalog es una herramienta de AWS que permite agrupar la creación de recursos de infraestructura en procedimientos estándar, agrupando todos los procesos necesarios para la creación de todos los elementos de infraestructura para un servicio dado. Ambas herramientas utilizadas dentro del stack permiten dar a la solución velocidad de desarrollo, estabilidad y escalabilidad.
Cómo lo hicimos?
Implementando el siguiente stack, que cuenta de 3 niveles:
- El 1er nivel se corresponde al Service Catalog para la creación directa de infraestructura;
- El 2do nivel se corresponde con set de scripts en Python, que implementan la comunicación entre el nivel de usuario y AWS;
- Y por último, el 3er nivel, que consiste en el set de proyectos y jobs de Rundeck, que sirven para ser invocados por usuarios finales o via API.
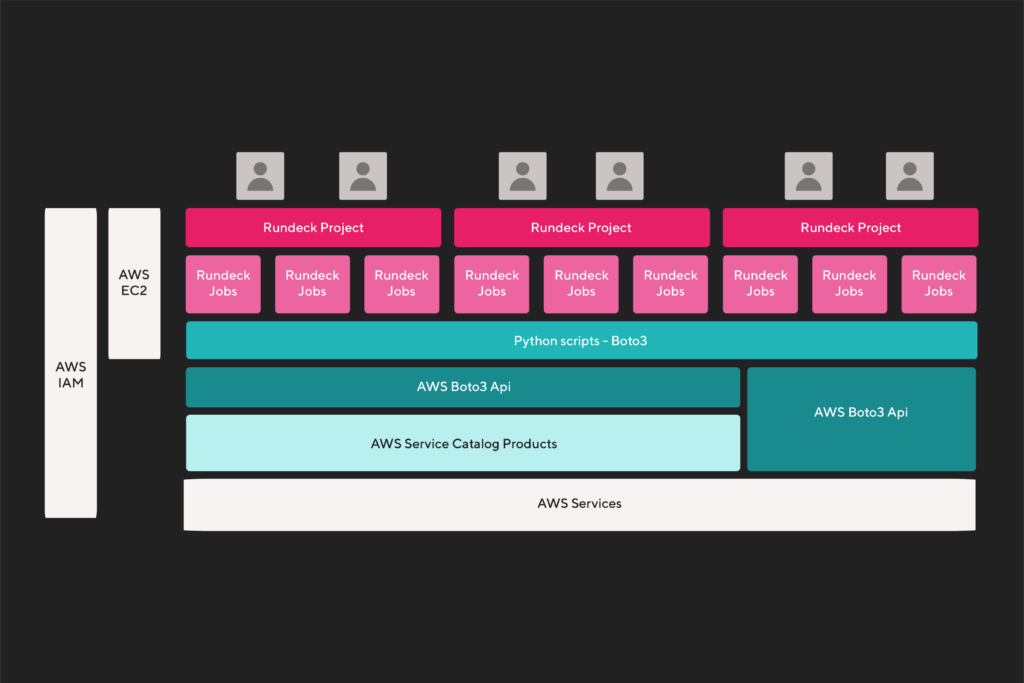
Ahora, vamos a cada uno de los niveles.
Nivel 1: Service Catalog
La capa de Service Catalog provee de productos estandarizados para creación de la infraestructura, garantizando que todos los recursos se creen con los criterios definidos, con los mismos atributos y estándares. Así mismo permite que sean auditados en el Service Catalog y se pueda administrar los stacks creados. Tiene la ventaja que estos productos pueden ser genéricos y que admitan ser utilizados para todas las áreas de negocios. De esta forma se minimiza la creación de productos en los portfolios de Service Catalog y el trabajo de mantenimiento de dicho código.
El hecho que los productos de Service Catalog sean genéricos para cada familia de recursos crea la necesidad que los mismos se parametricen y ejecuten con una capa de abstracción superior. Normalmente se requiere de conocimientos de infraestructura para validar los datos necesarios para los parámetros, y permisos de acceso a los diferentes recursos AWS para obtenerlos. Sin embargo, aún estos datos pueden localizarse siguiendo estándares, por lo cual esta capa de abstracción se automatiza utilizando scripts en python, quienes pueden acceder a la información necesaria via Boto3.
En este escenario, los portfolios de Service Catalog no necesitan ser accedidos directamente por los usuarios que requieran crear la infraestructura.
Nivel 2: Capa de Scripts basado en Python y Boto3
En esta capa se crea un set de scripts que utilizando Python y Boto3, son capaces de obtener los datos necesarios para generar los parámetros de ejecución de los productos de Service Catalog. Esta capa de scripts puede consultar a la API de AWS en busca de datos, puede localizar productos creados, concatenar ejecuciones de varios productos de Service Catalog o chequear resultados de un ejecución sin necesidad de un usuario que relacione estas acciones.
Proveen la flexibilidad necesaria para comunicar las diversas solicitudes de los usuarios con el set de productos de infraestructura disponible. Así mismo, los scripts pueden a la vez servir como módulos para la creación de diferentes servicios de infraestructura para múltiples proyectos de Rundeck.
Además, ante la necesidad de modificar la infraestructura creada, los scripts de python proveen funcionalidades de administración de los productos de Service Catalog ya creados, admitiendo la posibilidad que el usuario modifique y administre los productos ya deployados.
Al ejecutar los productos de Service Catalog de forma automatizada se provee de una capa extra de estandarización, ya que los mismos scripts son los encargados de crear los nombres de los recursos, evitando errores humanos o diferencias de criterios. Así mismo, se minimizan los errores al obtener todos los parámetros posibles vía los scripts, consultando a la API de AWS y evitando que los usuarios deban recopilar información por su cuenta.
El acceso disponible a los distintos servicios de AWS se gestiona mediante IAM, controlando los permisos otorgados a los roles que asume la instancia de Rundeck en los diferentes ambientes.
Nivel 3: Rundeck
Los jobs de Rundeck proveen la capa más alta de abstracción, generando la interfaz disponible al usuario. Pueden crearse tantos jobs como sea necesario para proveer un acceso simple a cada unidad de negocio para cada producto, introduciendo en las variables del job aquellas necesarias para parametrizar los scripts de python. Estas variables pueden ser transparentes al usuario, a quien solo se le solicita ingresar los campos mínimos requeridos para la creación de infraestructura, ya que Rundeck admite la posibilidad de setear parámetros de ejecución obligatorios u ocultos al usuario.
A nivel de los jobs de Rundeck es que se genera la capa superior de seguridad, segmentando los usuarios en proyectos y Jobs acorde a las funcionalidades que quieren habilitarseles. El acceso a estos proyectos y jobs es definido a nivel de las ACL de Rundeck para diversos grupos de usuarios, los cuales, dependiendo de el mecanismos de autenticación de Rundeck, pueden llevarse a cabo de diversas maneras. En el caso de Pomelo, la autenticación se realiza mediante el módulo JAAS de ldap, quien se conecta al servicio de ldap de Google.
Caso de uso: Transferencia de archivos con terceros basada en AWS Transfer Family y AWS Batch.
Para las áreas de Integraciones con terceros, la implementación de los servicios de transferencia de datos son cruciales para el negocio, creando la necesidad de contar con mecanismos que ágilmente provean de la infraestructura necesaria en los tiempos requeridos por el negocio. Sin embargo, esta creación de infraestructura es demandante en tiempo y recursos para las áreas de Plataforma e Infraestructura, quienes deben acompasar los tiempos del negocio con la creación de recursos de forma repetitiva.
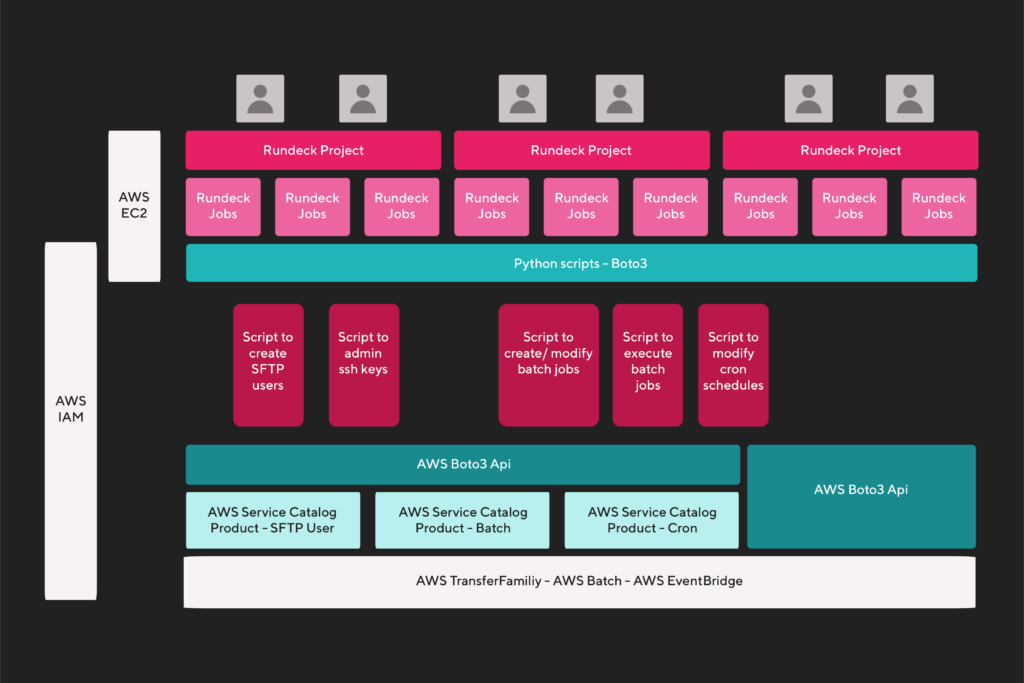
El stack de Rundeck + Service Catalog toma esta forma para la implementación de la solución. Los requerimientos del negocio implican la creación y administración de productos de transferencia de archivos y de los procesos batch que proporcionan la data a transferir.
Para ello se implementan los productos de service catalog que generan el usuario SFTP en el SFTP Transfer Server productivo y un producto de Service Catalog que genera los jobs definitions necesarios para generar los procesos de creación de datos para cada cliente, en el Batch productivo que sirve a las diferentes líneas de negocio. Es también necesario un producto que genere el cron para la ejecución de los reportes en el batch, lo cual se implementa mediante un cron en AWS EventBridge.
Buscando minimizar la complejidad al usuario, buscamos que únicamente los jobs requieran aquellos parámetros que no pueden ser adquiridos via request de Boto3 a la api de AWS, detectando que únicamente es necesario parametrizar los siguientes datos:
- Nombre del cliente;
- Identificador de Pomelo;
- Hora de los reportes a ejecutar;
- Unidad de negocios que implementa la transferencia de datos;
- Clave pública de ssh del cliente.
Con estos datos y una interfaz limitada desde los jobs, los usuarios son capaces de administrar toda la compleja infraestructura generada por las capas subyacentes.

Los scripts de python en este caso, además de iniciar la creación de los producto de service catalog involucrados, proveen también una interfaz al usuario para administrar la infraestructura creada:
- Permiten listar, agregar y borrar claves públicas de sftp en los usuarios creados
- Permiten listar y ejecutar los jobs creados.
Estas funcionalidades se logran combinando acciones directas sobre AWS vía Boto3 con actualizaciones de los productos de Service Catalog que hayan sido creados desde este stack.

Este job localiza por el usuario el producto de Service Catalog original y lo actualiza, modificando únicamente los parámetros relevantes.
Qué ganamos implementando este stack?
Ahora que detallamos todo lo que hicimos, llegó el momento de contar lo que obtuvimos con la experiencia. Directo y al punto: ganamos velocidad, seguridad y confiabilidad para el negocio, para el usuario y para los equipos de infraestructura. Abajo traemos más detalles:
- Reducción de 85% en tiempos en la creación del recurso
- Tiempo invertido por infraestructura para crear un batch directo desde el Service Catalog: 1,5hs
- Tiempo invertido desde Rundeck por un usuario final: 10 minutos
- Mantenimiento de estándares de nomenclatura, los recursos son nombrados por los scripts de creación
- Reducción de errores humanos, ya que los parámetros de entrada se reducen a un set básico.
- Control y seguimiento de las ejecuciones y modificaciones realizadas en Rundeck.
- Independencia del departamento de integraciones con terceros, quienes pueden responder inmediatamente a la necesidad del cliente.
Esperamos que les haya gustado y les sea útil para su producto o negocio! Siempre testeamos y creamos tecnología a la velocidad de Pomelo y, por supuesto, van a poder leerlo todo sobre lo que hacemos y qué hacemos acá en Pomelo Words! 😄
Ofrece tus propias tarjetas
Utiliza nuestra tecnología moderna para la emisión, procesamiento y gestión de pagos con tarjetas de crédito, débito y prepago.


