
En una de nuestras Talks by Pomelo, el evento donde nuestro equipo de tecnología nos cuenta al detalle sus experimentaciones y lo que vienen haciendo, contamos cómo nos apoyamos en AWS Service Catalog para armar Rocket, nuestra Internal Developer Platform (IDP). Y, en particular, mencionamos que utilizamos CloudFormation para definir los templates de productos internos en nuestros portfolios de Service Catalog.
Durante la charla, también mencionamos que el soporte de CloudFormation para recursos de AWS es bastante completo, aunque en algunos casos hay features específicas de ciertos productos que no están soportadas. Y, si necesitáramos incluir productos de proveedores diferentes a AWS, no existe soporte nativo desde CloudFormation para hacerlo. Por lo tanto, no sería descabellado pensar que esta es una limitación fatal a la hora de decidirnos por el uso de Service Catalog o CloudFormation para soportar nuestros procesos internos de desarrollo.
En este artículo vamos a echar luz sobre una de las features más potentes de CloudFormation, Custom Resource Types, la cual nos va a permitir utilizar funcionalidades no soportadas de forma nativa, manipular recursos provistos por otros proveedores de servicios en la nube, ¡y sortear muchos otros obstáculos de ese tipo! Con estos pro tips vamos a tener superpoderes a la hora de describir nuestra Infraestructura como Código con Cloudformation.
Introducción al CloudFormation Public Registry
El servicio de CloudFormation incluye un registro público de extensiones de terceros, disponibles para instalar en nuestra propia cuenta de AWS. Estas pueden ser de las siguientes familias:
- Modules: fragmentos de templates que pueden ser reutilizados de manera consistente en múltiples Stacks.
- Hooks: permiten definir una lógica de validación para la configuración de los recursos en un Stack.
- Resource types: son elementos que se pueden utilizar en la sección “Resources” de cualquier Template de CloudFormation. Se utilizan de la misma forma que aquellos descritos en la referencia oficial de CloudFormation (como, por ejemplo, AWS::ApiGatewayV2::Api). En este blogpost nos vamos a concentrar particularmente en esta familia de extensiones.
El registro público nos permite acceder a extensiones que distintos proveedores de servicios en la nube, u otras empresas o comunidades de usuarios, han disponibilizado. Además, es posible registrar de manera privada, en nuestra propia cuenta de AWS, extensiones desarrolladas por nosotros mismos. Esto nos abre un mundo completo de posibilidades para extender la funcionalidad de nuestros portfolios de Service Catalog.
Casos de uso para custom Resource Types
Queremos hacer este post tech, pero soft en cuanto a código o detalles de implementación extremadamente técnicos, alentando a los desarrolladores a aprovechar los recursos de documentación oficiales provistos por AWS, que vamos a enumerar más adelante.
Antes de avanzar, aclararemos rápidamente un tema que puede generar dudas: entre todos los tipos nativos de CloudFormation existe un recurso llamado AWS::CloudFormation::CustomResource, al que también se lo puede referenciar mediante el shorthand Custom::String. Este ofrece un soporte mucho más limitado para la implementación de lógica de aprovisionamiento de infraestructura, en comparación con los custom Resource Types a los que nos referimos en este artículo, por lo que simplemente vamos a ignorarlo para evitar confusiones.
¿Qué implementaciones de custom resource types podemos ofrecer como ejemplo?
Tipos custom oficiales provistos por third-parties
Algunas organizaciones de renombre ofrecen soporte nativo en CloudFormation para sus principales funcionalidades, vía el registro público de extensiones. Por ejemplo, Atlassian soporta el manejo de diferentes tipos de recursos de su servicio Opsgenie, mediante los tipos Atlassian::Opsgenie::{Integration,Team,User}.
Por otro lado, hay organizaciones que disponibilizan el código fuente de extensiones de Cloudformation para que uno mismo las despliegue en su infraestructura. Por ejemplo, en el repositorio de código AWS Integrations and Automations se proporcionan implementaciones compatibles con:
- GitHub y GitLab para repositorios de código fuente,
- Cloudflare y Fastly para soporte de CDNs,
- Pagerduty para manejo de incidentes,entre otras.
Estas se pueden desplegar de manera privada, es decir, de forma tal que queden solamente visibles en la cuenta en la que se desplieguen.
Casos de uso adicionales que podríamos implementar nosotros mismos
Adicionalmente, podría ocurrir que, por alguna necesidad de negocio particular, necesitemos agregar soporte en CloudFormation para algún otro tipo de elementos, como por ejemplo:
- una base de datos en un proveedor cloud diferente;
- elementos de chaos testing con Gremlin, como Templates, Gamedays, u otros;
- registrar repositorios de código como targets de escaneo de vulnerabilidades en un servicio como Snyk;
Para cualquiera de estos casos podríamos abrir nuestro IDE preferido y poner manos a la obra para desarrollar una integración a medida. En las siguientes secciones vamos a enfocarnos en esto, contándoles a grandes rasgos cómo es el esquema de desarrollo de un custom resource type.
Desarrollando una extensión de Resource Type
Modelado de los recursos del tipo
Lo primero que necesitamos hacer, antes de escribir la primera línea de código, es describir mediante un documento en formato JSON la estructura de nuestro tipo custom. Esto está detallado en la sección Modeling resource types de la documentación oficial de la CLI de CloudFormation.
Pensar en el modelo antes de escribir código nos va a ayudar, como implementadores, a entender qué datos necesitamos recabar del usuario para poder crear instancias de nuestro tipo. No solo eso, sino que también nos obligará a entender la relación existente entre las distintas propiedades que se podrían modelar.
Además, la definición del modelo va a determinar la “interfaz de usuario” (UI) del tipo, es decir, cómo un usuario va a declarar una instancia de este tipo de recurso en sus templates de CloudFormation. Con esto nos referimos a qué campos debe necesariamente especificar, cuáles son opcionales, el tipo de cada uno de ellos y la documentación que le ayude a entender sus respectivas funciones.
Lenguajes soportados
La utilidad para desarrollar extensiones soporta, a través de plugins provistos oficialmente por AWS, los siguientes lenguajes de programación:
- Java
- Golang
- Python
- Typescript
La herramienta también ofrece la posibilidad de que desarrollemos plugins para cualquier otro lenguaje de programación, si lo necesitáramos.
En nuestra opinión, la mayor ventaja de utilizar esta herramienta para desarrollar un tipo custom, es que se hará cargo de generar todo el esqueleto de código necesario para que nosotros simplemente nos ocupemos de codificar la interacción con las APIs relevantes para nuestro tipo. Solamente nos solicita que implementemos un conjunto puntual de operaciones, que serán invocadas en determinados eventos de cambio de estado en CloudFormation.
A lo largo de este artículo vamos a utilizar Python para el desarrollo de los ejemplos de código. Para ilustrar mínimamente el flujo de desarrollo, les mostraremos cómo inicializar el esqueleto de código para un tipo custom a continuación. Haremos de cuenta que queremos agregar soporte para targets de escaneo de código de Snyk (MyOrg::Snyk::CodeRepositoryTarget). El único requisito mínimo es contar con un entorno de desarrollo para Python, incluyendo el gestor de paquetes pip.
- Instalar la CLI de CloudFormation, y el plugin de desarrollo para Python
$ pip install cloudformation-cli cloudformation-cli-python-plugin … Successfully installed Jinja2-3.1.2 Werkzeug-2.3.6 botocore-1.24.46 cloudformation-cli-0.2.32 cloudformation-cli-python-plugin-2.1.8 markupsafe-2.1.3 s3transfer-0.5.2
- Inicializar un nuevo proyecto de tipo custom en su propio directorio
$ mkdir my-custom-type $ cd my-custom-type $ cfn init Initializing new project Do you want to develop a new resource(r) or a module(m) or a hook(h)?. >> r What's the name of your resource type? (Organization::Service::Resource) >> MyOrg::Snyk::CodeRepositoryTarget Select a language for code generation: [1] python36 [2] python37 [3] python38 [4] python39 (enter an integer): >> 4 Use docker for platform-independent packaging (Y/n)? This is highly recommended unless you are experienced with cross-platform Python packaging. >> y Initialized a new project in /private/tmp/test/my-custom-type
Veamos cómo es el esqueleto de código que la herramienta generó:
$ tree . ├── README.md ├── docs │ ├── README.md │ ├── memo.md │ └── tag.md ├── example_inputs │ ├── inputs_1_create.json │ ├── inputs_1_invalid.json │ └── inputs_1_update.json ├── myorg-snyk-coderepositorytarget.json ├── requirements.txt ├── resource-role.yaml ├── rpdk.log ├── src │ └── myorg_snyk_coderepositorytarget │ ├── __init__.py │ ├── handlers.py │ └── models.py └── template.yml 5 directories, 15 files
Veamos brevemente qué propósito tienen algunos de estos archivos generados:
- myorg-snyk-coderepositorytarget.json: este es el archivo en que vamos a modelar los recursos del tipo custom. Cada vez que lo modifiquemos, será necesario ejecutar el comando cfn validate, para asegurarnos que adhiera al Resource provider definition schema, documentado aquí. Si la validación es correcta, debemos también ejecutar cfn generate para que se actualicen el archivo de modelos y la documentación del tipo custom;
- docs/*.md: estos archivos, automáticamente generados mediante el comando cfn generate, contienen la documentación de cada una de las propiedades especificadas en el modelo;
- src/myorg_snyk_coderepositorytarget/models.py: aquí hay código Python autogenerado mediante cfn generate, con la definición de las diferentes clases que utilizaremos al codificar las operaciones;
- src/myorg_snyk_coderepositorytarget/handlers.py: en este archivo codificaremos las operaciones del tipo, como describiremos en la próxima sección;
- example_inputs/: este directorio contiene diferentes definiciones de “recursos de ejemplo”, para ayudarnos con el testing de las operaciones.
Operaciones
Si está familiarizado con CloudFormation, sabrá que cuando opera con Stacks, los recursos que las componen pueden ser creados, modificados y eliminados. Aunque no sea obvio, detrás de escena, Cloudformation también realiza la lectura de recursos individuales y el listado de colecciones de recursos. Esto es relevante porque, para desarrollar nuestra propia extensión de tipo custom, necesitamos saber cuál de estas operaciones es obligatoria implementar, cuáles simplemente son recomendadas y el motivo por el cuál son necesarias. Detallamos a continuación cuál es el caso por cada una:
- Crear: obligatoria. Debe registrar aquel identificador (o conjunto de identificadores) que se puedan utilizar a posteriori para operar sobre este recurso en invocaciones futuras.
- Leer: obligatoria. Utilizando el o los identificadores mencionados en la operación anterior, debe poder reconstruir el modelo del recurso por completo. Esta operación suele ser invocada al hacer actualizaciones de un stack, y al solicitar una detección de drift de los recursos.
- Modificar: opcional. De no estar implementada, toda actualización del recurso será efectuada mediante la creación de un recurso de reemplazo, y la destrucción del original. En caso de que se la implemente, es bueno tener en cuenta que haber invertido el esfuerzo necesario en un buen modelo nos permitirá simplificar la lógica aquí, ya que no necesitaremos preocuparnos por cambios en las propiedades que no los soportan (como aquellas de sólo lectura). Asimismo, no será estrictamente necesario validar las distintas combinaciones de propiedades soportadas, si el modelado ya se encarga de hacerlo.
- Eliminar: obligatoria. Esta operación simplemente debe eliminar el recurso. Generalmente se invoca cuando se elimina un stack, cuando un recurso se elimina de un template, o cuando un recurso es reemplazado por otro al efectuarse una actualización que requiera “re-creación”.
- Listar: opcional. Se invoca cuando CloudFormation debe listar información de contexto de un conjunto de recursos del tipo, por ejemplo al mostrar un selector de recursos como valores de parámetros, en la interfaz de usuario de CloudFormation.
El objeto “modelo”
Al implementar cada una de las operaciones mencionadas en el punto anterior, veremos que en “la firma” de cada método del código generado por la herramienta se incluyen uno o más referencias a un objeto “modelo”, ya sea en el objeto que representa la request (de tipo ResourceHandlerRequest) o en el que representa la respuesta (del tipo ProgressEvent).
@resource.handler(Action.CREATE) def create_handler( session: Optional[SessionProxy], request: ResourceHandlerRequest, callback_context: MutableMapping[str, Any], ) -> ProgressEvent: model = request.desiredResourceState progress: ProgressEvent = ProgressEvent( status=OperationStatus.IN_PROGRESS, resourceModel=model, ) …
Dependiendo de la operación en cuestión, CloudFormation nos provee de cierta información sobre el recurso sobre el cuál se va a operar, mediante este objeto pasado como parámetro. A su vez, dependiendo de la operación, CloudFormation también puede esperar que la respuesta del método que implementa la operación contenga información del recurso, tras la aplicación de la operación. A continuación daremos algunos ejemplos relevantes, aunque recomendamos revisar la documentación oficial con la especificación completa del contrato de las operaciones:
@resource.handler(Action.CREATE)El objeto request.desiredResourceState contiene toda la información necesaria para construir un recurso del tipo, de acuerdo a lo declarado en el modelo.
El modelo en el objeto devuelto por la función, en caso de haberse completado correctamente la operación, debe contener todos los atributos definidos, incluyendo el o los identificadores que se le hubiera asignado. Es muy útil en este caso simplemente devolver el resultado de una sucesiva invocación del handler de lectura:
return read_handler(session, request, callback_context)Si la creación del recurso está en progreso y debemos chequear periódicamente si la operación finalizó para poder retornar un status exitoso, podemos simplemente retornar un objeto
ProgressEvent( status=OperationStatus.IN_PROGRESS, resourceModel=model, )
donde model es un objeto modelo con, como mínimo, el identificador debidamente definido. Una sucesiva invocación del handler por parte de CloudFormation deberá utilizar el identificador para averiguar si el recurso finalmente fue creado con éxito, en cuyo caso deberá devolver el resultado de la invocación del handler de lectura. Esto nos permitirá optimizar el tiempo de ejecución de nuestros handlers, algo relevante cuando su runtime de ejecución es AWS Lambda. Este patrón se puede repetir en todos los otros handlers, excepto el de lectura.
@resource.handler(Action.UPDATE)En este caso, el objeto request contiene dos atributos con propósitos bien específicos:
- request.previousResourceState: describe el estado del recurso, de acuerdo a lo reportado por el handler READ previo a la actualización.
- request.desiredResourceState: nos informa cómo quiere el usuario que el recurso se vea luego de la actualización.
@resource.handler(Action.DELETE)Aquí, request.desiredResourceState contendrá un objeto modelo con, como mínimo, un identificador del recurso. Tener en cuenta que el resto de los atributos del recurso podrían no venir proporcionados en la request.
Si el borrado del recurso se efectúa correctamente, el objeto ProgressEvent devuelto no debe contener un objeto modelo:
return ProgressEvent( status=OperationStatus.SUCCESS, resourceModel=None, ) @resource.handler(Action.READ)
En este caso, las condiciones de la request son similares a las del handler DELETE. En cuanto al comportamiento de salida, vale la pena comentar que este handler debe retornar un objeto ProgressEvent como máximo tras 30 segundos.
@resource.handler(Action.LIST)Este handler, como el de READ, debe retornar un objeto ProgressEvent en 30 segundos o menos. Además, debe retornar SUCCESS o FAILED (es decir, no hay posibilidad de continuar la ejecución mediante un OperationStatus.IN_PROGRESS), pero puede utilizarse un token de paginación para partir la búsqueda en múltiples páginas (y, consecuentemente, en múltiples llamadas diferentes al handler).
En el atributo resourceModels del objeto ProgressEvent debe retornar una lista con los identificadores de los recursos encontrados.
Despliegue
Una vez que tenemos un conjunto mínimo de operaciones implementadas, podemos ejecutar el siguiente comando para orquestar el despliegue de todos los componentes necesarios:
$ cfn submit –region us-east-2 –set-defaultEsto disponibiliza en nuestra cuenta de AWS, de manera privada, la primera versión del tipo, para que podamos comenzar a utilizarlo en nuestros templates de CloudFormation.
A medida que vayamos iterando la implementación podemos volver a ejecutar ese comando, de modo tal que en nuestra cuenta quede disponible la última versión con las mejoras que hayamos incorporado.
A continuación dejamos un pequeño diagrama explicativo que describe los subcomandos disponibles en la herramienta de CLI cfn:
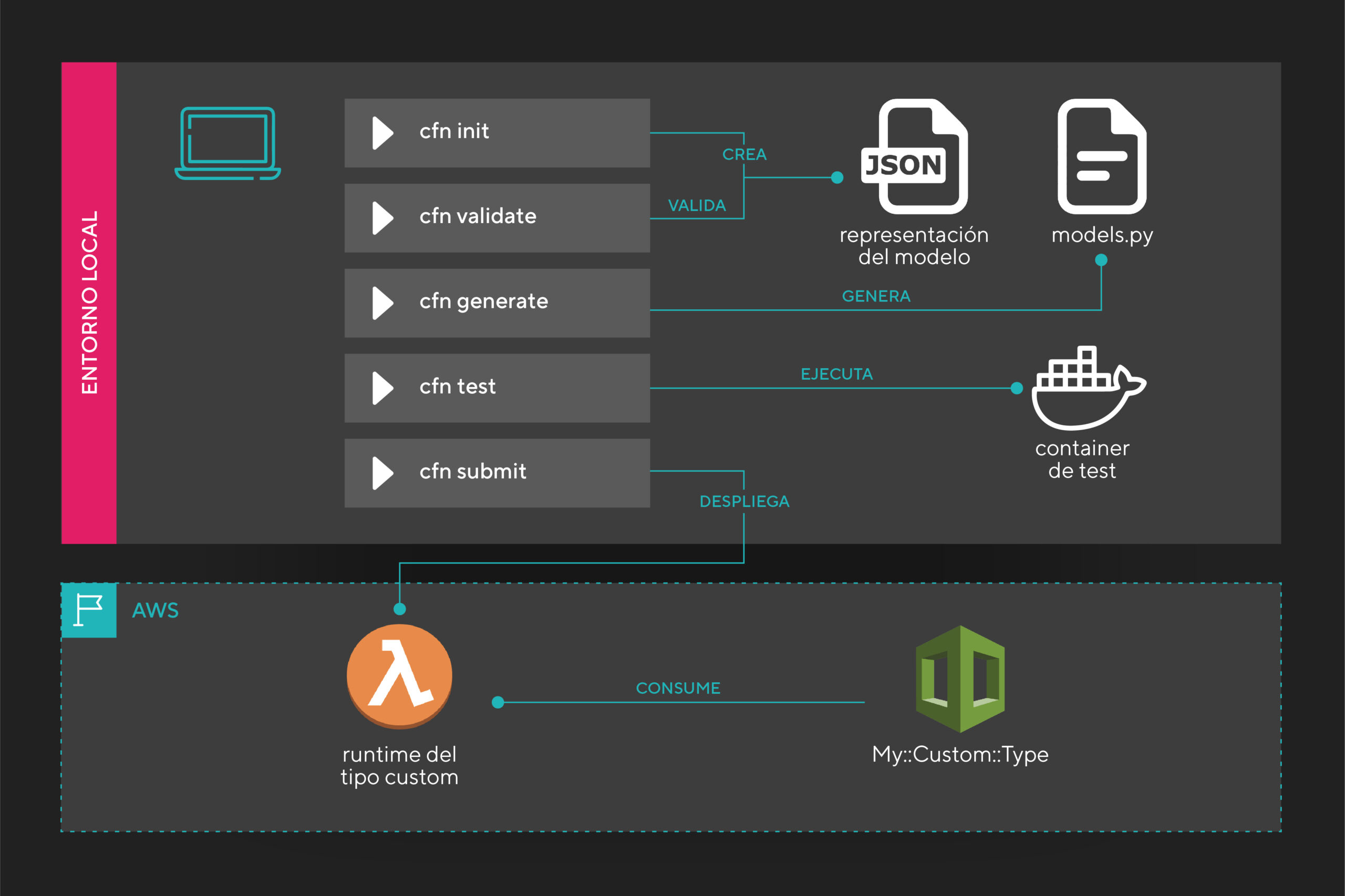
Errores comunes
Manejo de credenciales
Al implementar la lógica de manejo de recursos en una API externa a AWS, necesitaremos proporcionar algún tipo de credencial (ya sea un API key, un par de client ID/secret de OAuth, etc.) para poder autenticar nuestras llamadas de manera correcta.
Si podemos asumir que es posible compartir esa credencial para todos los recursos manejados en una misma cuenta y región de AWS, la forma correcta de realizar esto es a través de Type Configurations.
Podemos hacer un paralelismo entre estas Type Configurations y las variables de entorno de cualquier runtime de aplicaciones: nosotros, como desarrolladores de un tipo de recurso custom, asumimos que quien instala nuestra extensión (que podemos ser nosotros mismos, obviamente) proporcionará los valores necesarios para que la misma funcione correctamente. De esta forma podemos mantener el código de la extensión libre de credenciales.
Es importante remarcar que además, esto nos permite mantener los stacks de CloudFormation libres de credenciales, provistos ya sea en templates (con valores hard-coded) o como valores de parámetros. Es muy importante que esto sea así para evitar que los valores de las credenciales se filtren en lugares inesperados, como ocurriría, por ejemplo, si las mismas se proporcionan como un atributo del recurso parte del primaryIdentifier .
Vale la pena destacar que los valores de las Type Configurations pueden hacer referencia a secretos almacenados en AWS SSM Parameter Store y AWS Secrets Manager, con lo que se pueden mantener seguros de punta a punta.
Recursos adicionales
Con este artículo queríamos subrayar algunos aspectos normalmente pasados por alto en otros artículos que se pueden encontrar en internet, respecto al desarrollo de tipos custom para CloudFormation. Sin embargo, recomendamos a cualquier persona que se embarque en una tarea como esta, que se apoye en los siguientes recursos provistos oficialmente por AWS:
- Descripción paso a paso del proceso: Using Python to manage third-party resources in AWS CloudFormation (manteniendo una mirada crítica, ya que allí se recomienda utilizar una propiedad del modelo del recurso para almacenar un token).
- La documentación oficial del framework, con la referencia completa: CloudFormation Command Line Interface documentation (en particular, ver la sección “Creating resource types”).
Conclusión
Como vimos en este artículo, agregar soporte en CloudFormation para algún tipo de recurso que no esté disponible de manera nativa, aunque pueda parecer algo complejo, realmente puede ser una tarea amena. Esto, siempre y cuando estemos familiarizados con el patrón de desarrollo y las abstracciones que nos proporciona el framework de la CLI de CloudFormation.
Tener esta herramienta a nuestra disposición nos permite seguir apoyándonos en CloudFormation aún en aquellos casos en los que debemos manejar infraestructura no provista por AWS, lo que puede ser de vital importancia cuando, como en Pomelo, hacemos uso extensivo de este paradigma de Infraestructura como Código, específicamente al trabajar con AWS Service Catalog como herramienta de auto aprovisionamiento de recursos para nuestros equipos de desarrollo.
¡Esperamos que este blog post les haya servido! Ahora es su turno de poner manos a la obra y desplegar sus propios custom resource types 🚀.
